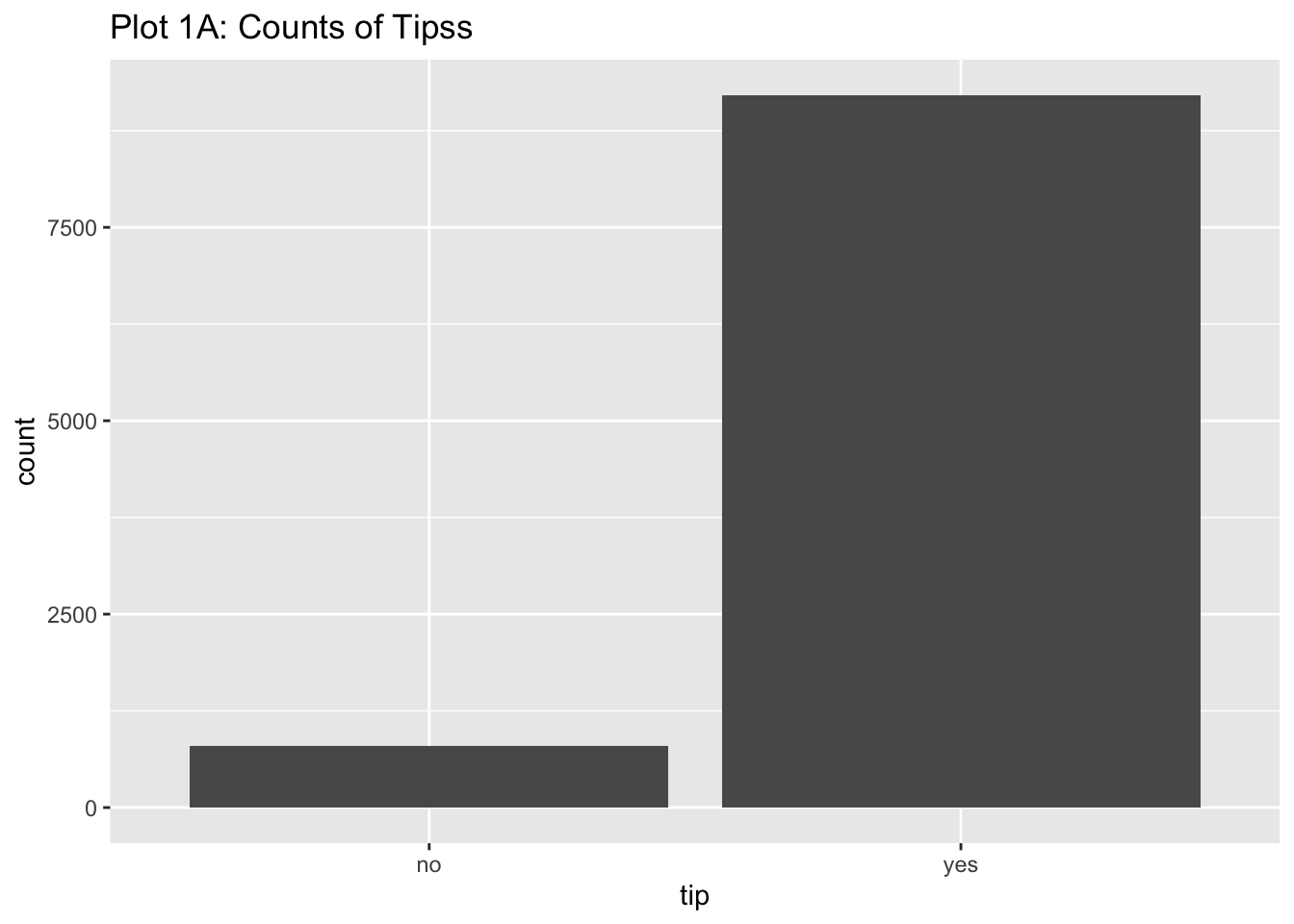
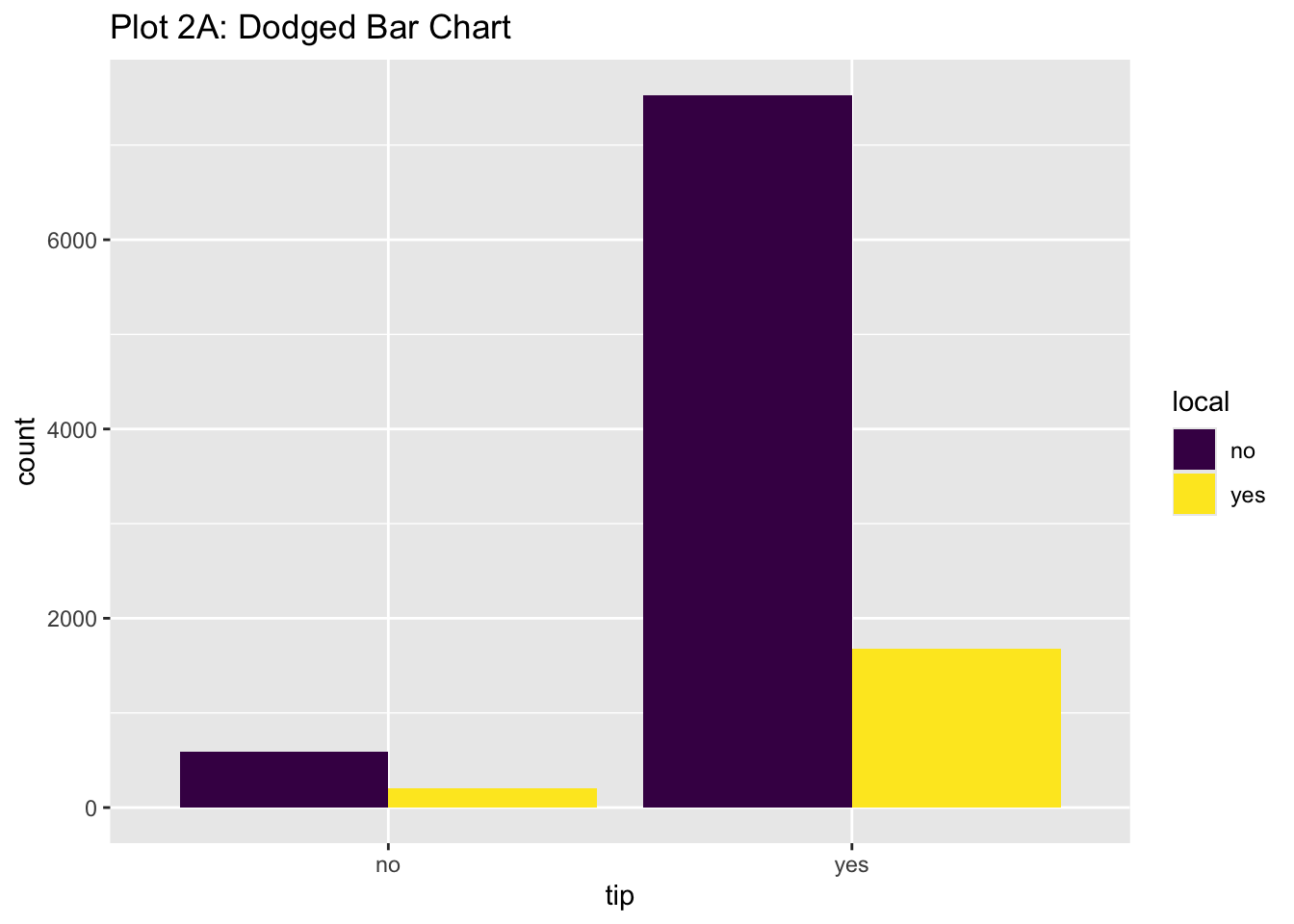
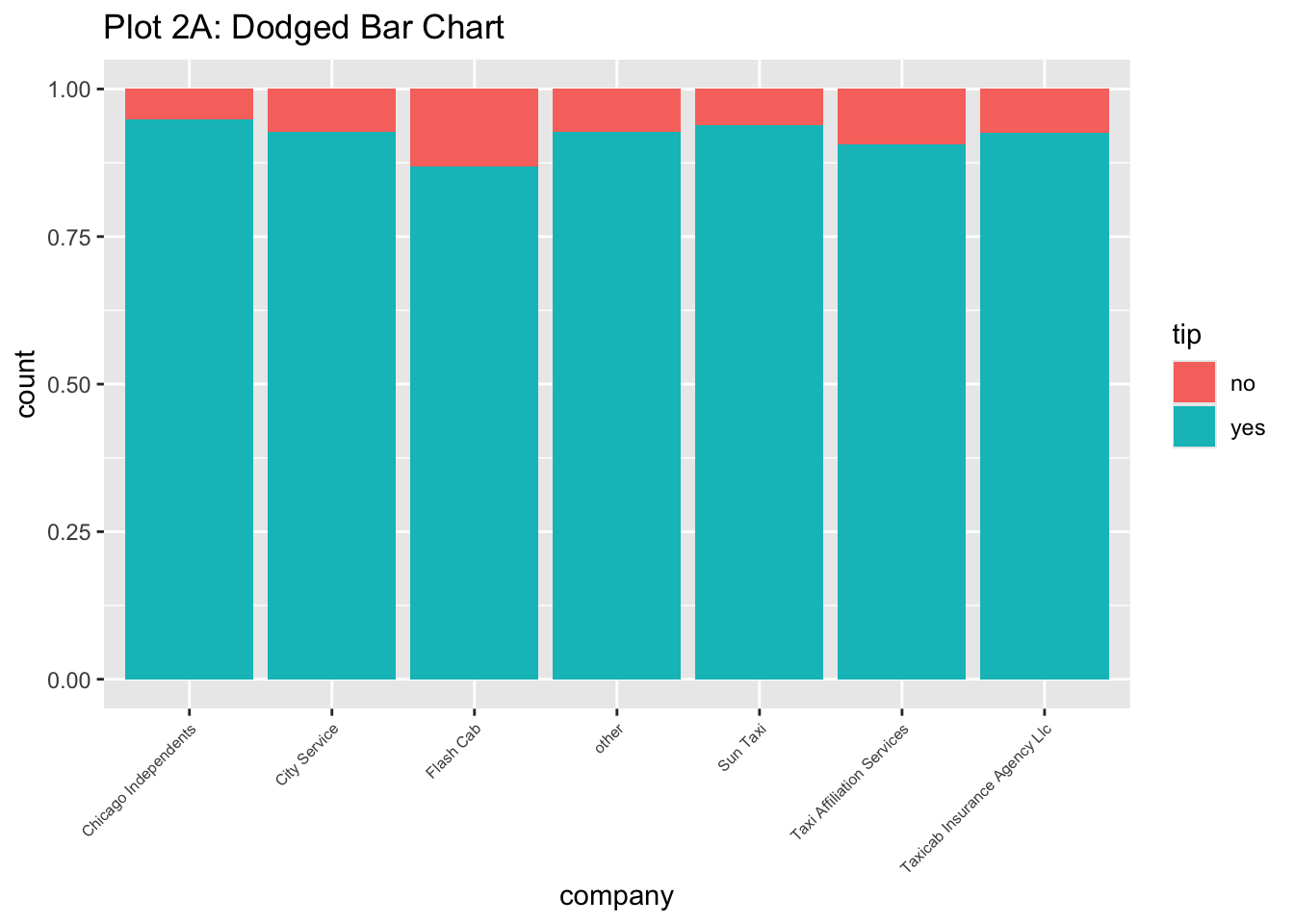
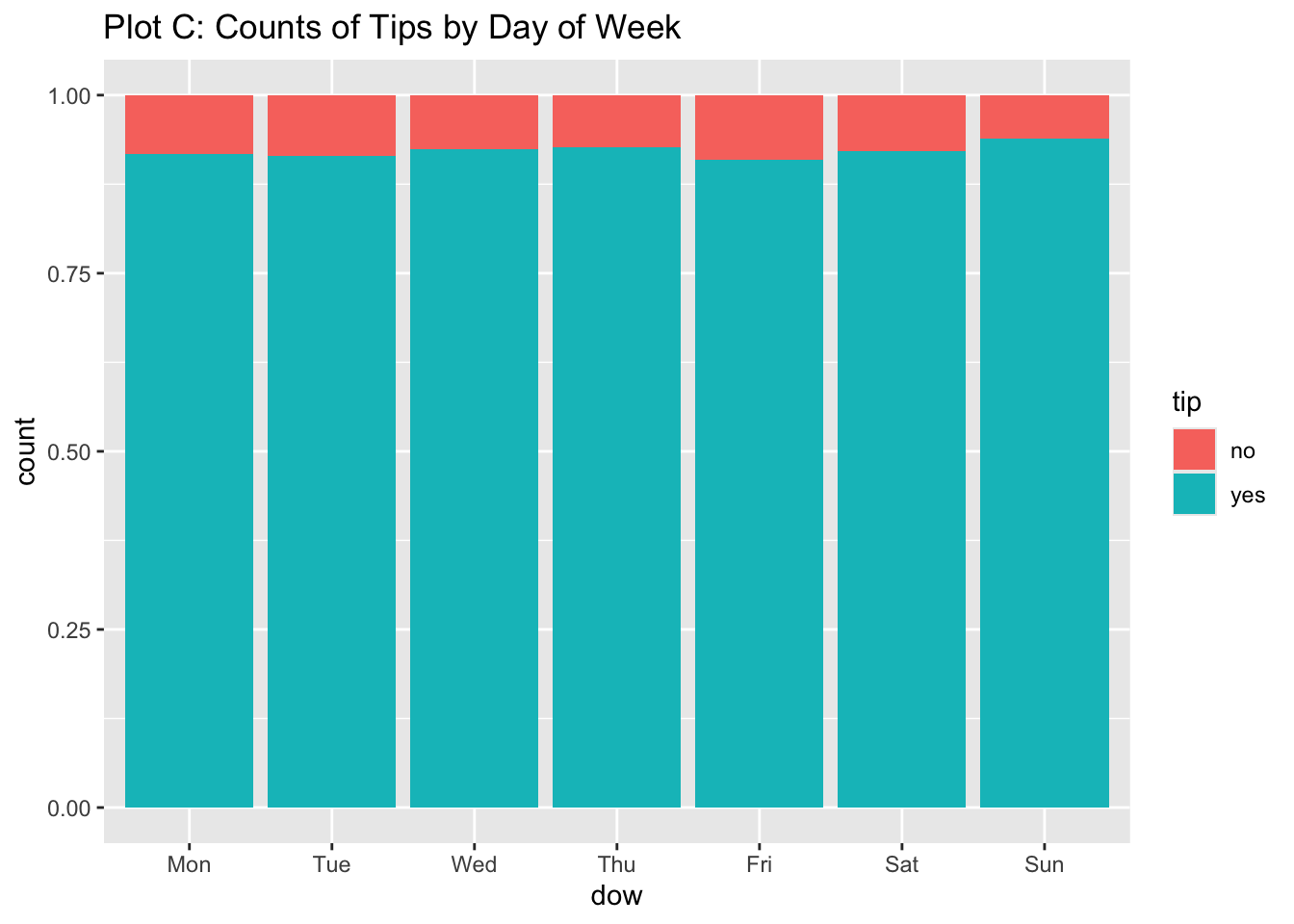
Rows: 254,654
Columns: 9
$ rownames <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18…
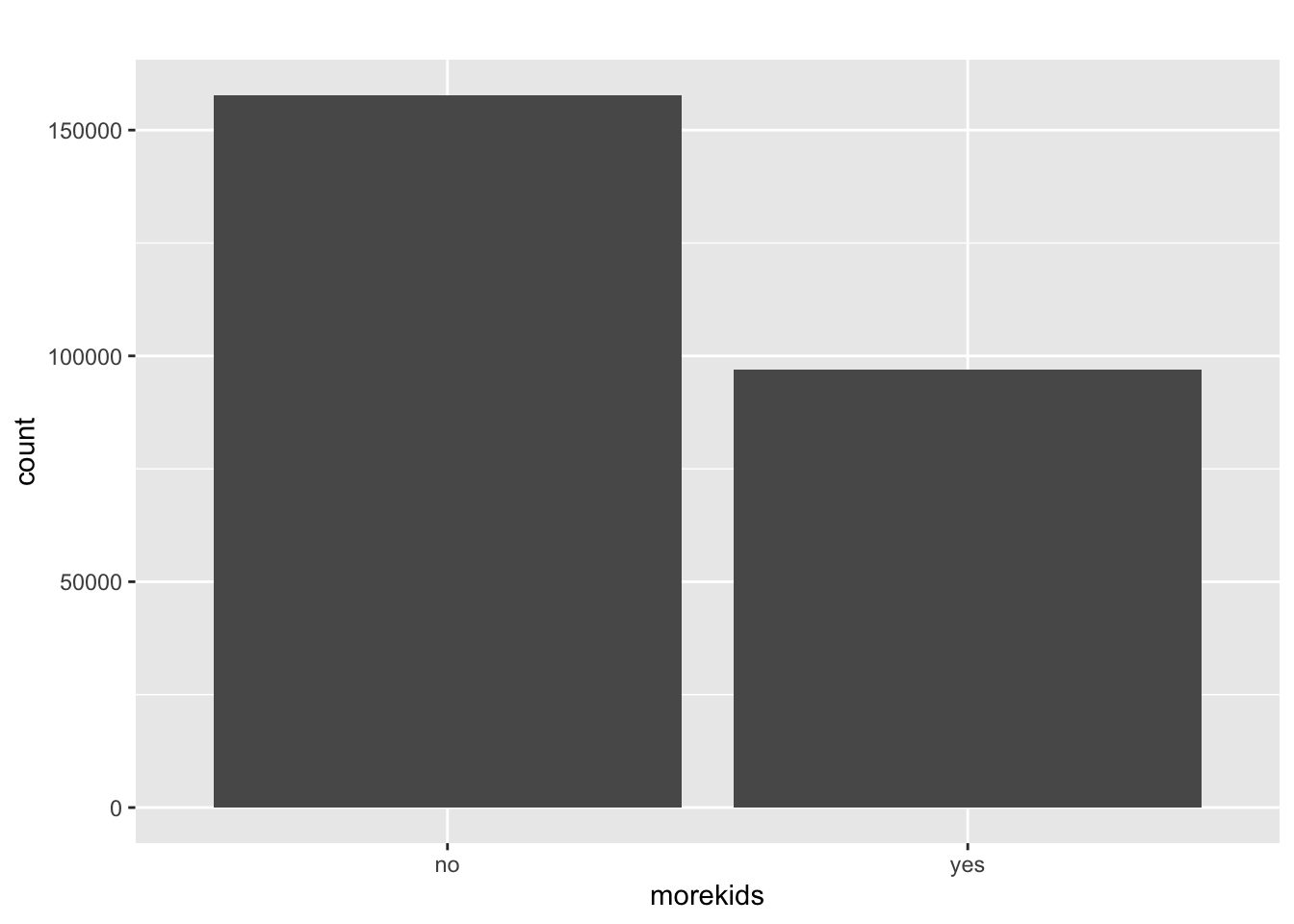
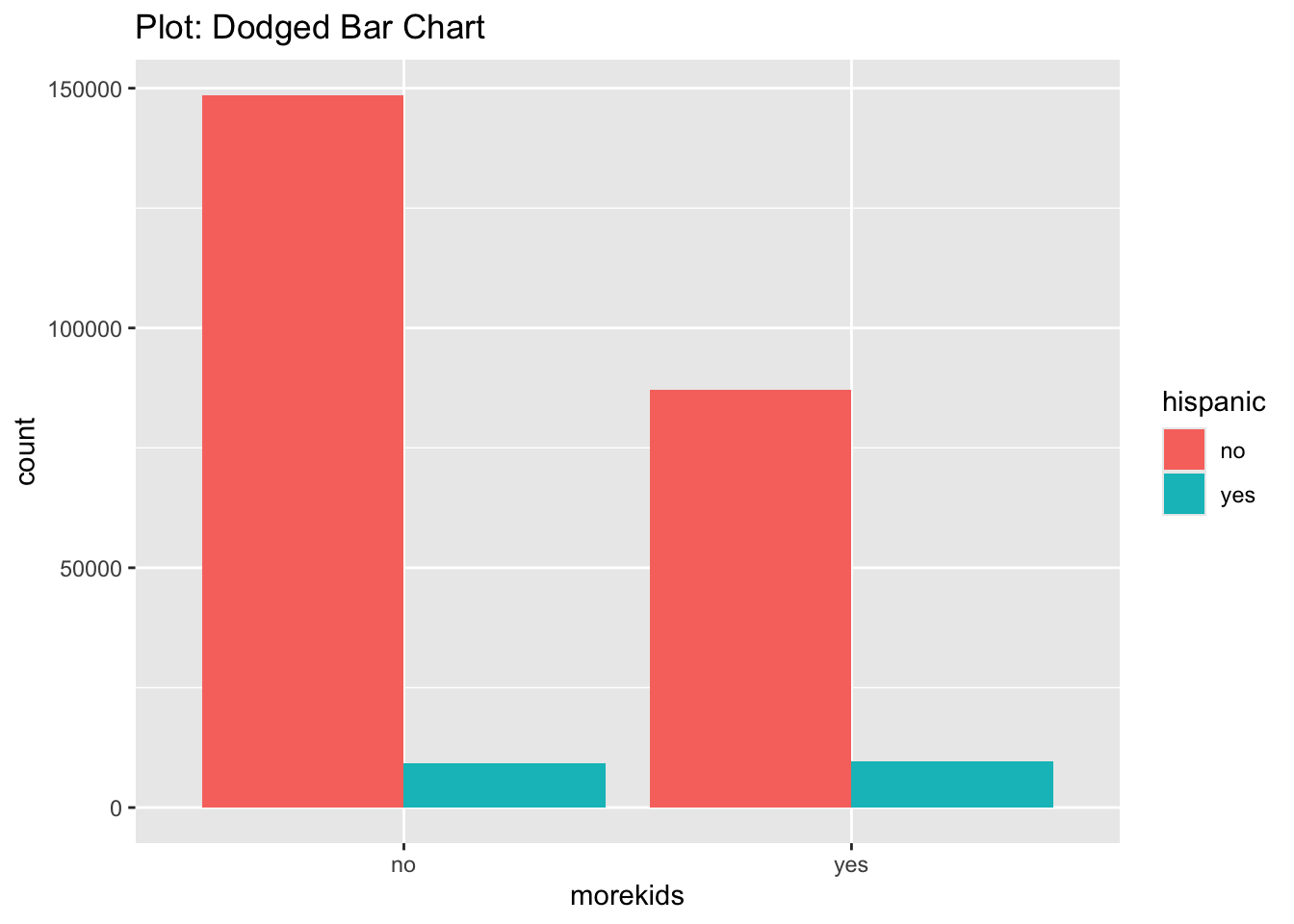
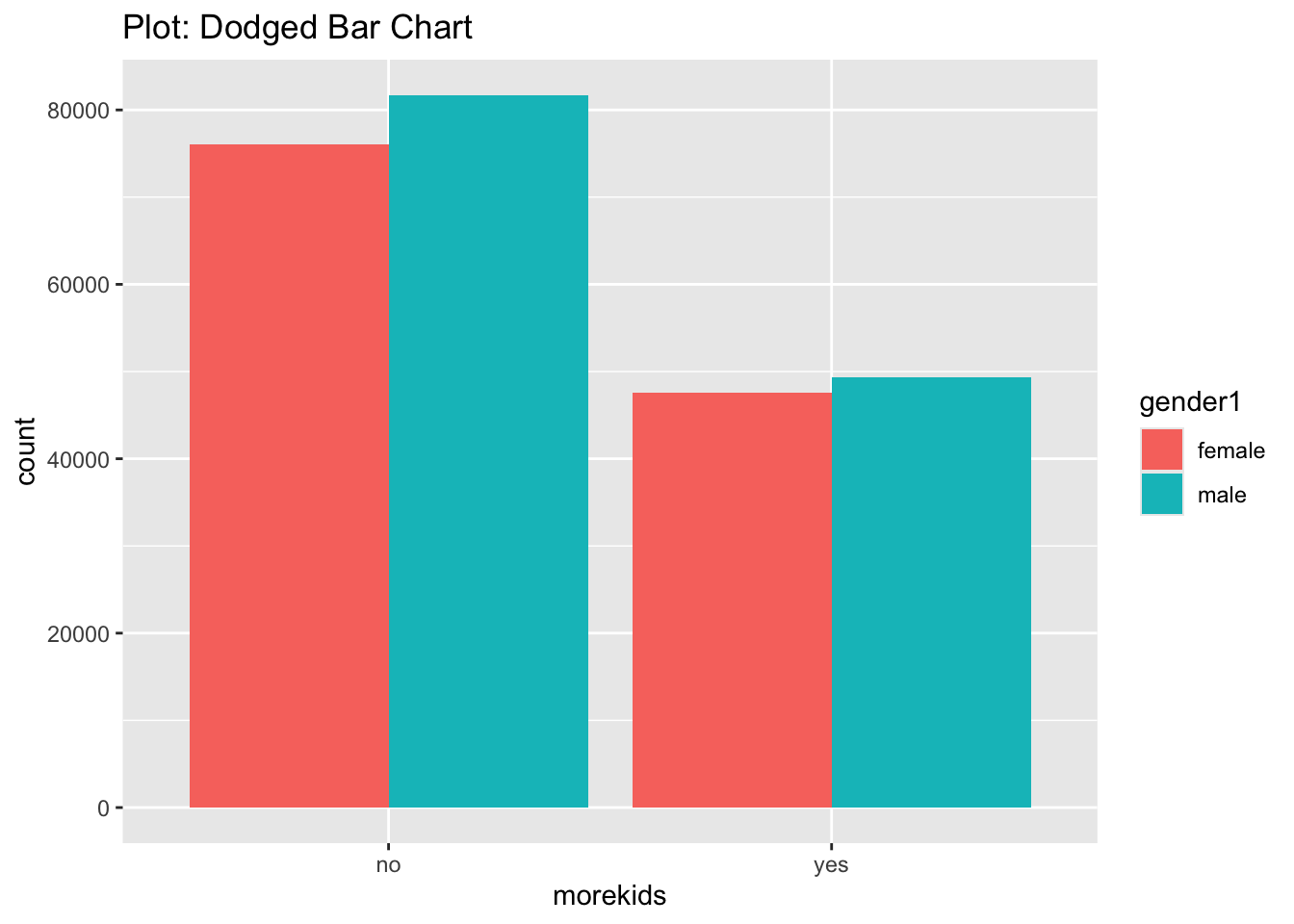
$ morekids <fct> no, no, no, no, no, no, no, no, no, no, yes, no, no, no, no, …
$ gender1 <fct> male, female, male, male, female, male, female, male, female,…
$ gender2 <fct> female, male, female, female, female, female, male, male, mal…
$ age <dbl> 27, 30, 27, 35, 30, 26, 29, 33, 29, 27, 28, 28, 35, 34, 32, 2…
$ afam <chr> "no", "no", "no", "yes", "no", "no", "no", "no", "no", "no", …
$ hispanic <fct> no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, n…
$ other <fct> no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, n…
$ work <dbl> 0, 30, 0, 0, 22, 40, 0, 52, 0, 0, 0, 52, 52, 52, 8, 7, 0, 40,…