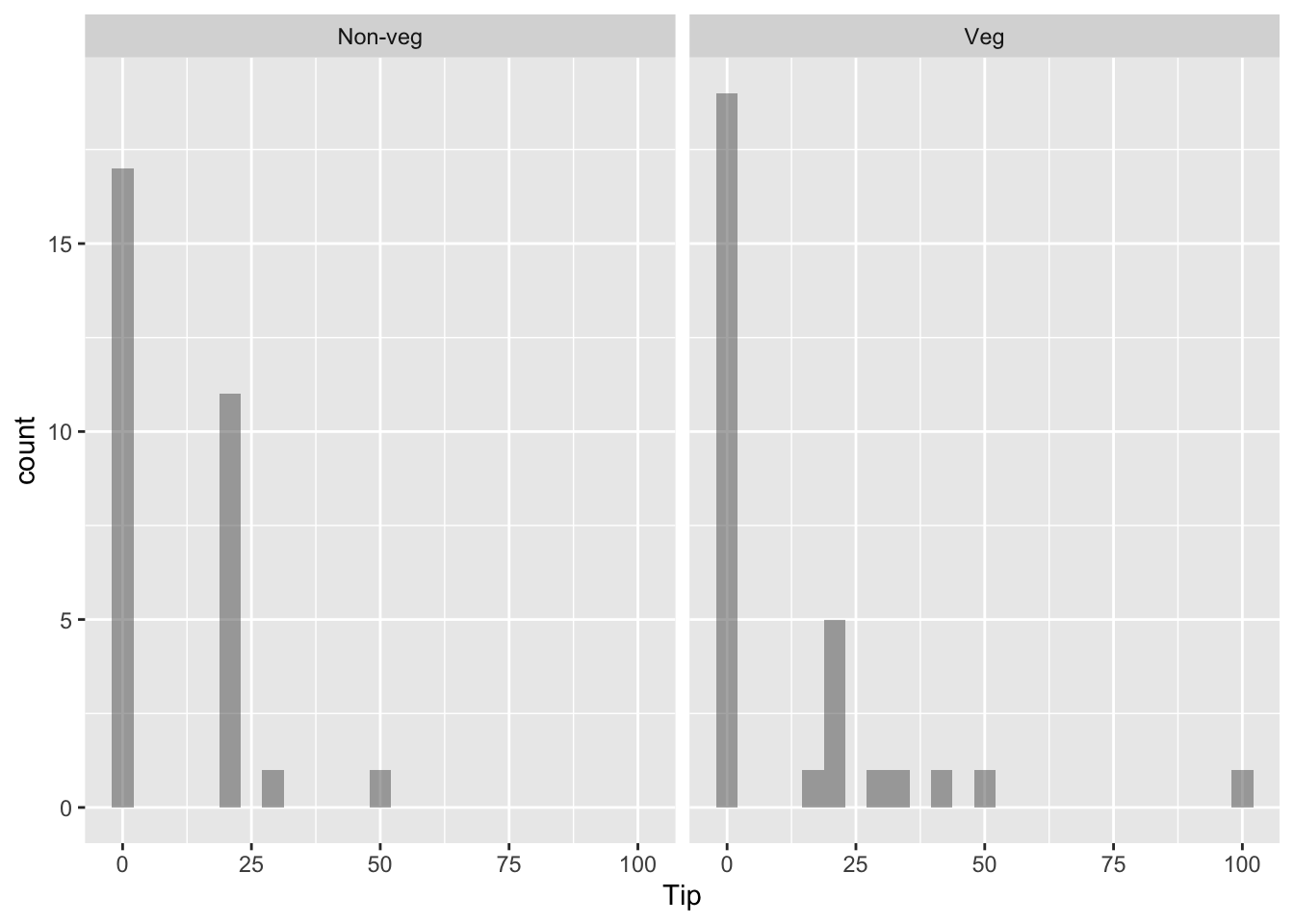
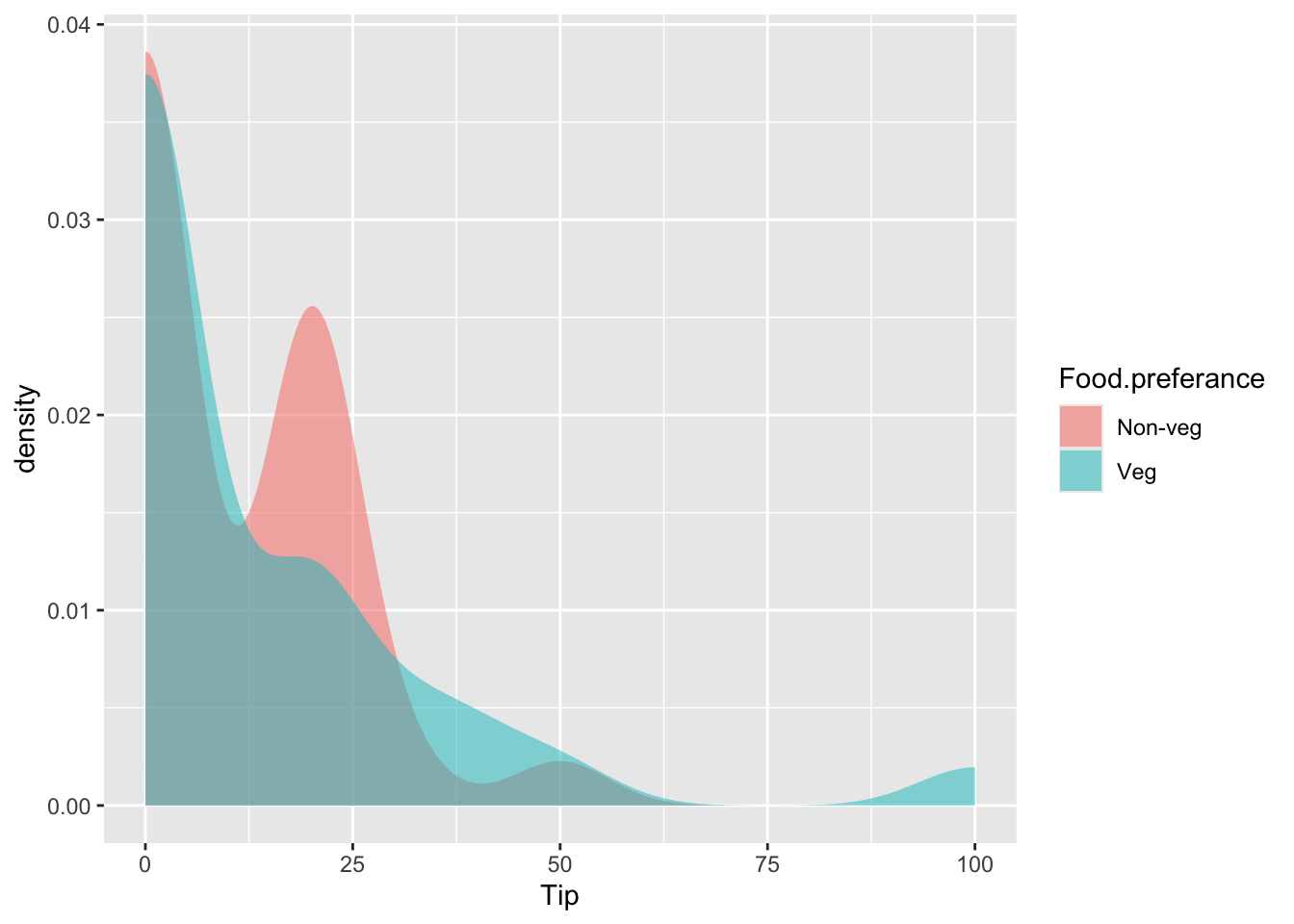
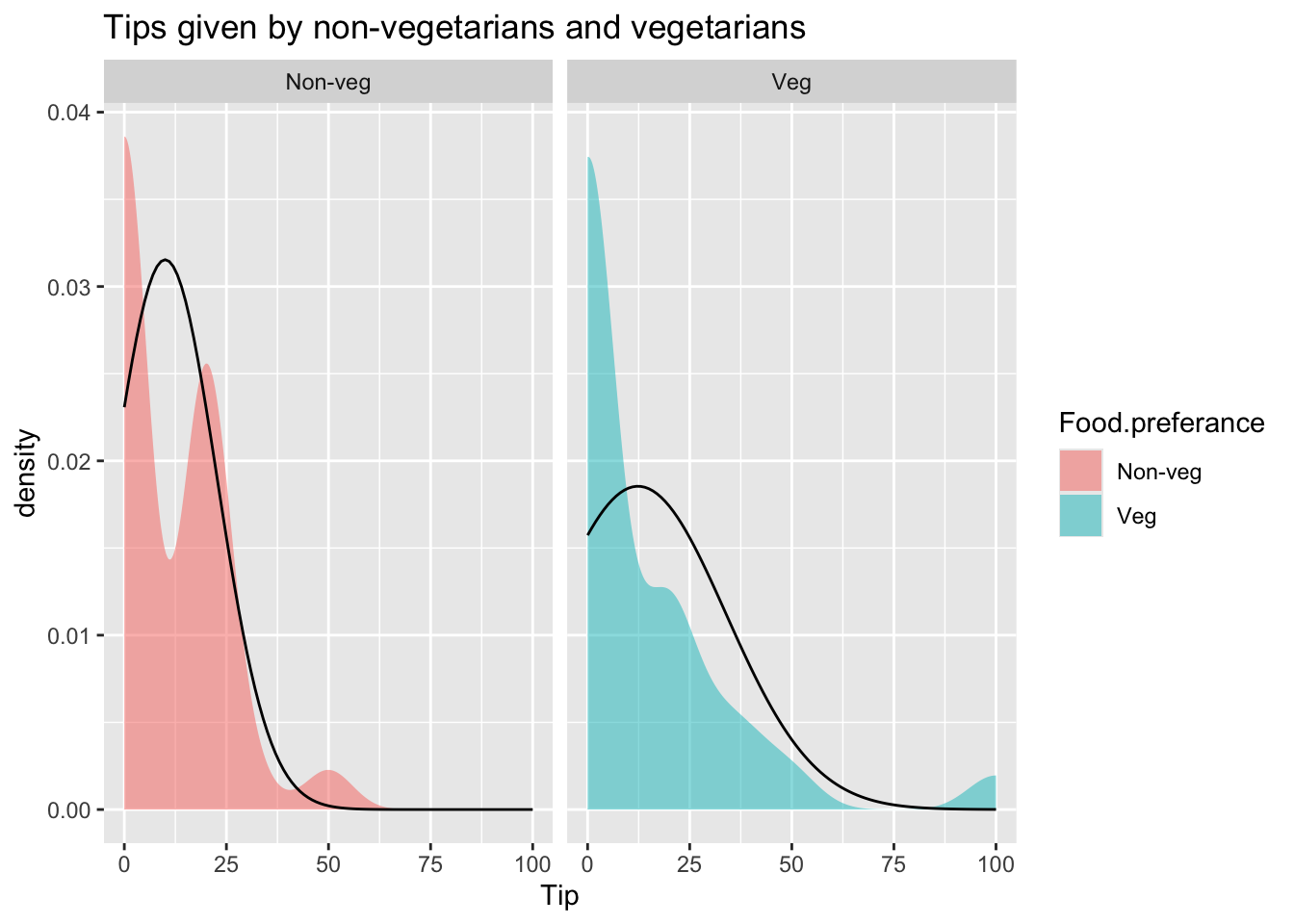
tip <-read.csv("../../data/tip.csv")print(head(tip))
Name Gender Food.preferance Tip
1 Aanya Female Veg 0
2 Adit Male Veg 0
3 Aditi Female Veg 20
4 Akash Male Non-veg 0
5 Akshita Female Non-veg 0
6 Anandita Female Non-veg 0
Research Question: Is there a significant difference in the average tip amount given by non-vegetarians compared to vegetarians?
inspect(tip)
categorical variables:
name class levels n missing
1 Name character 58 60 0
2 Gender character 2 60 0
3 Food.preferance character 2 60 0
distribution
1 Ananya (3.3%), Simran (3.3%) ...
2 Female (50%), Male (50%)
3 Non-veg (50%), Veg (50%)
quantitative variables:
name class min Q1 median Q3 max mean sd n missing
1 Tip integer 0 0 0 20 100 11.16667 17.83556 60 0
tip %>%crosstable(Tip~Food.preferance) %>%as_flextable()
Shapiro-Wilk normality test
data: tip_modified$Tip[tip_modified$Food.preferance == "Veg"]
W = 0.6286, p-value = 1.661e-07
p value = 0.0000001661
p-value for both the groups (veg and non-veg) is less than 0.05, as a result we reject the null hypothesis, the data for both groups is not normally distributed.
we fail to reject the null hypothesis, no significant statistical difference between the means of non-vegetarian and vegetarian groups when it comes to tipping.
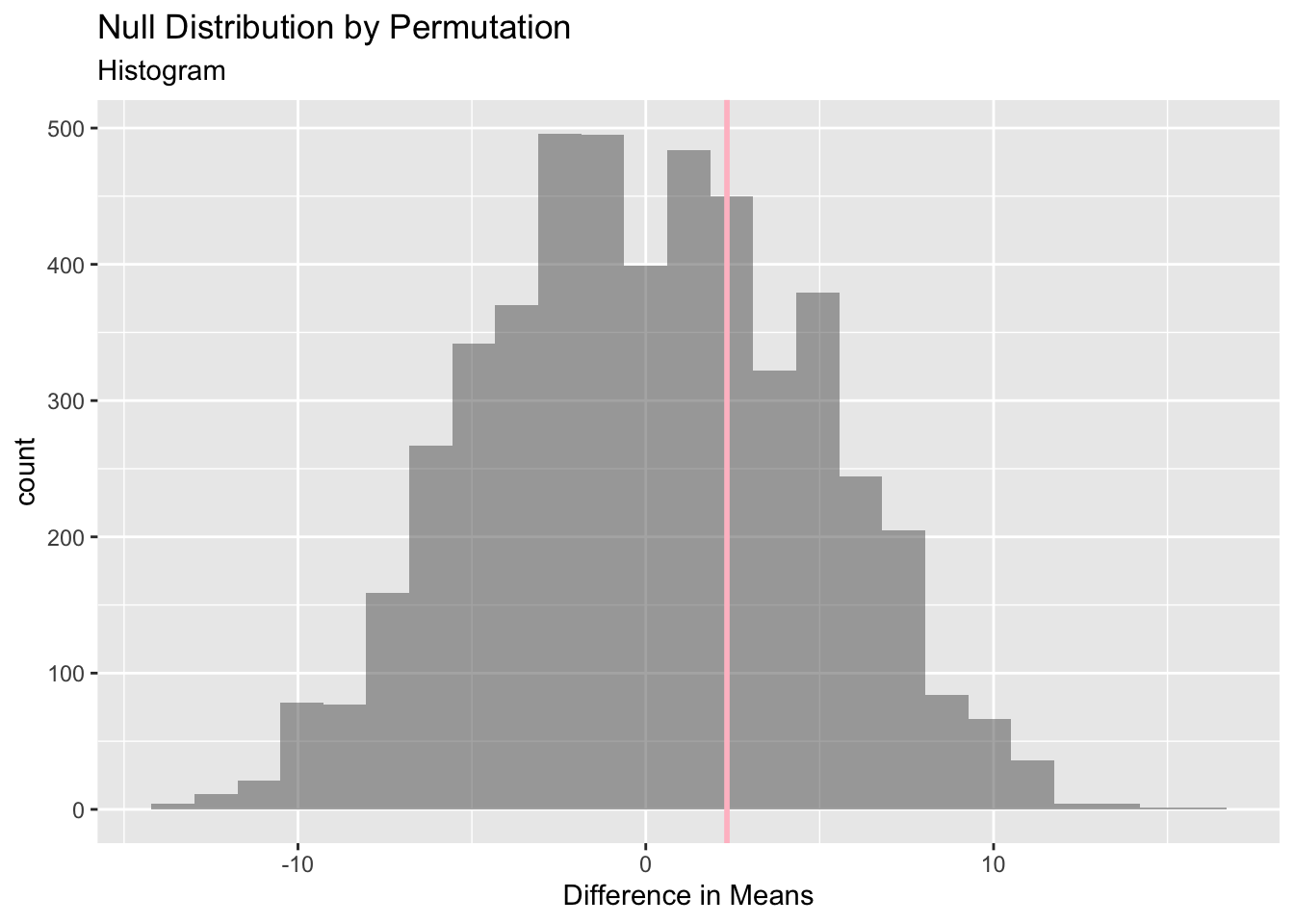
-Permutation test
null_dist_Tip <-do(4999) *diffmean(data =tip_modified, Tip ~shuffle(Food.preferance))head(null_dist_Tip, n =15)
gf_histogram(data = null_dist_Tip, ~ diffmean, bins =25) %>%gf_vline(xintercept = obs_diff_tips, colour ="pink", linewidth =1,title ="Null Distribution by Permutation", subtitle ="Histogram") %>%gf_labs(x ="Difference in Means")
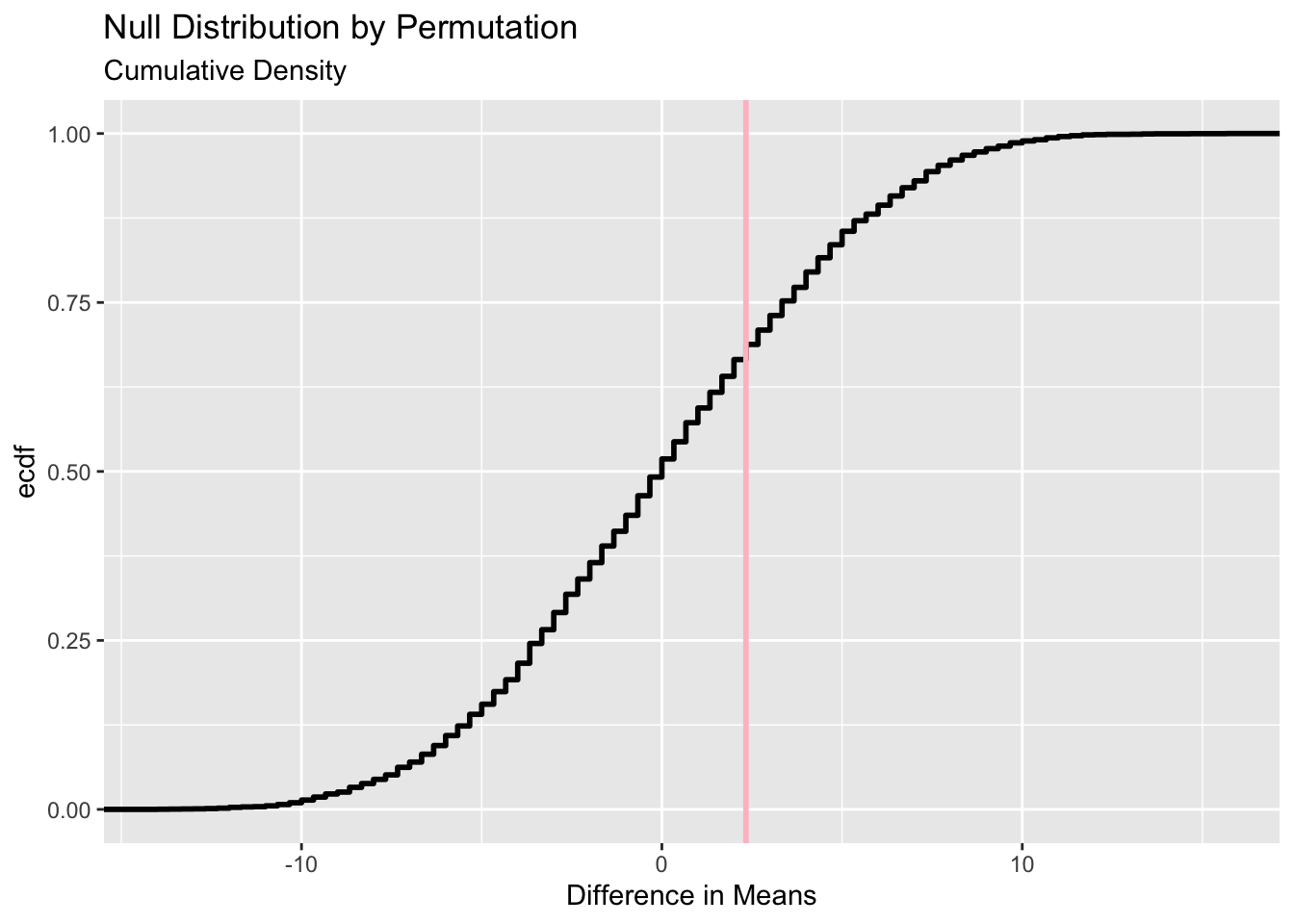
###gf_ecdf(data = null_dist_Tip, ~ diffmean, linewidth =1) %>%gf_vline(xintercept = obs_diff_tips, colour ="pink", linewidth =1,title ="Null Distribution by Permutation", subtitle ="Cumulative Density") %>%gf_labs(x ="Difference in Means")
1-prop1(~ diffmean <= obs_diff_tips, data = null_dist_Tip)
prop_TRUE
0.312
The observed difference in tips is not beyond anythimg that we could generate with permutations; therefore, there is again no significant different in tips between the vegetarian and non vegetarian groups. We fail to reject the null hypothesis.
————————–
-Mann-Whitney Test
—data is not normally distributed (not Gaussian), and the variances of the two groups are significantly different. This indicates that the assumption of normality is not satisfied, while the assumption of equal variances is satisfied.