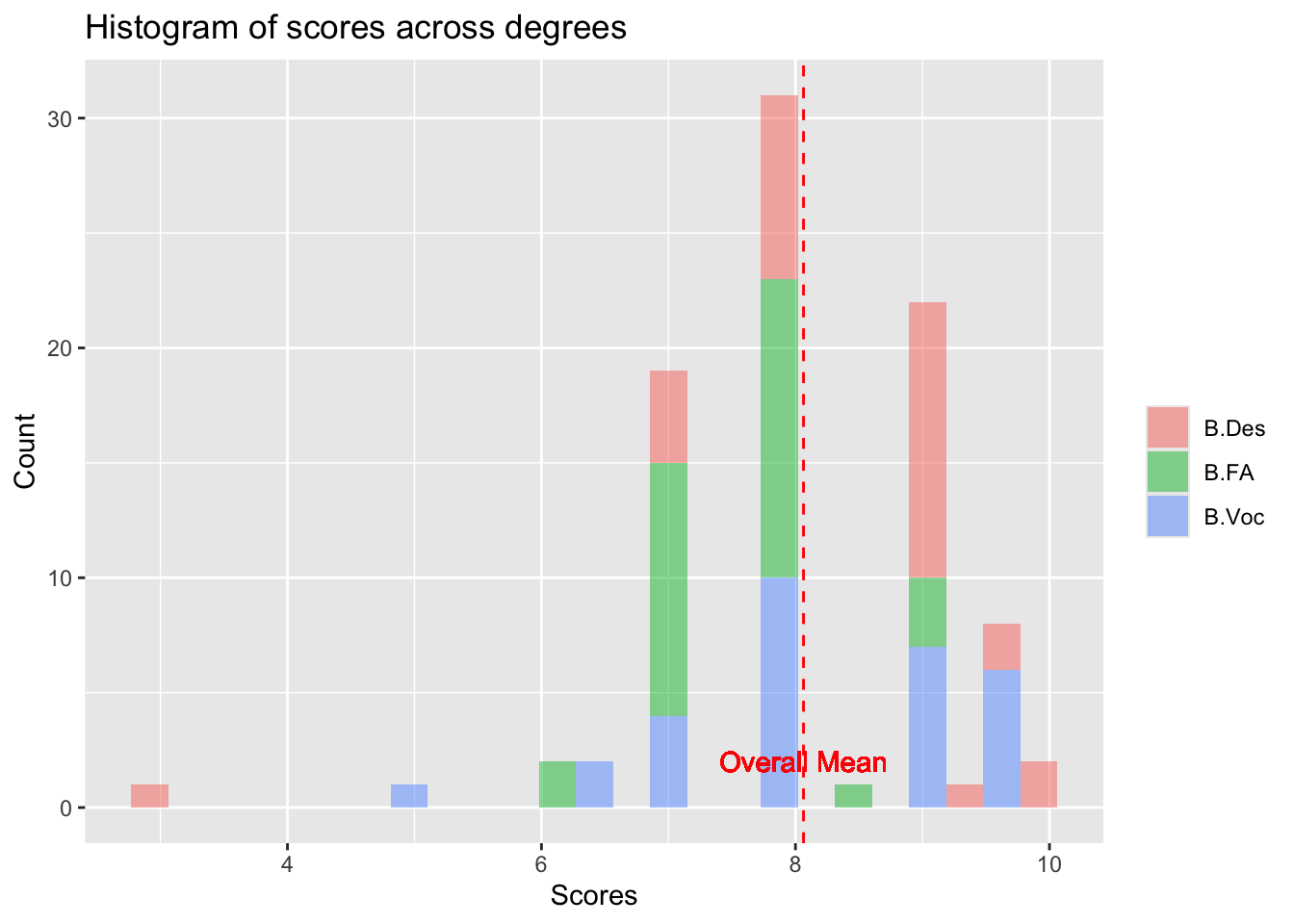
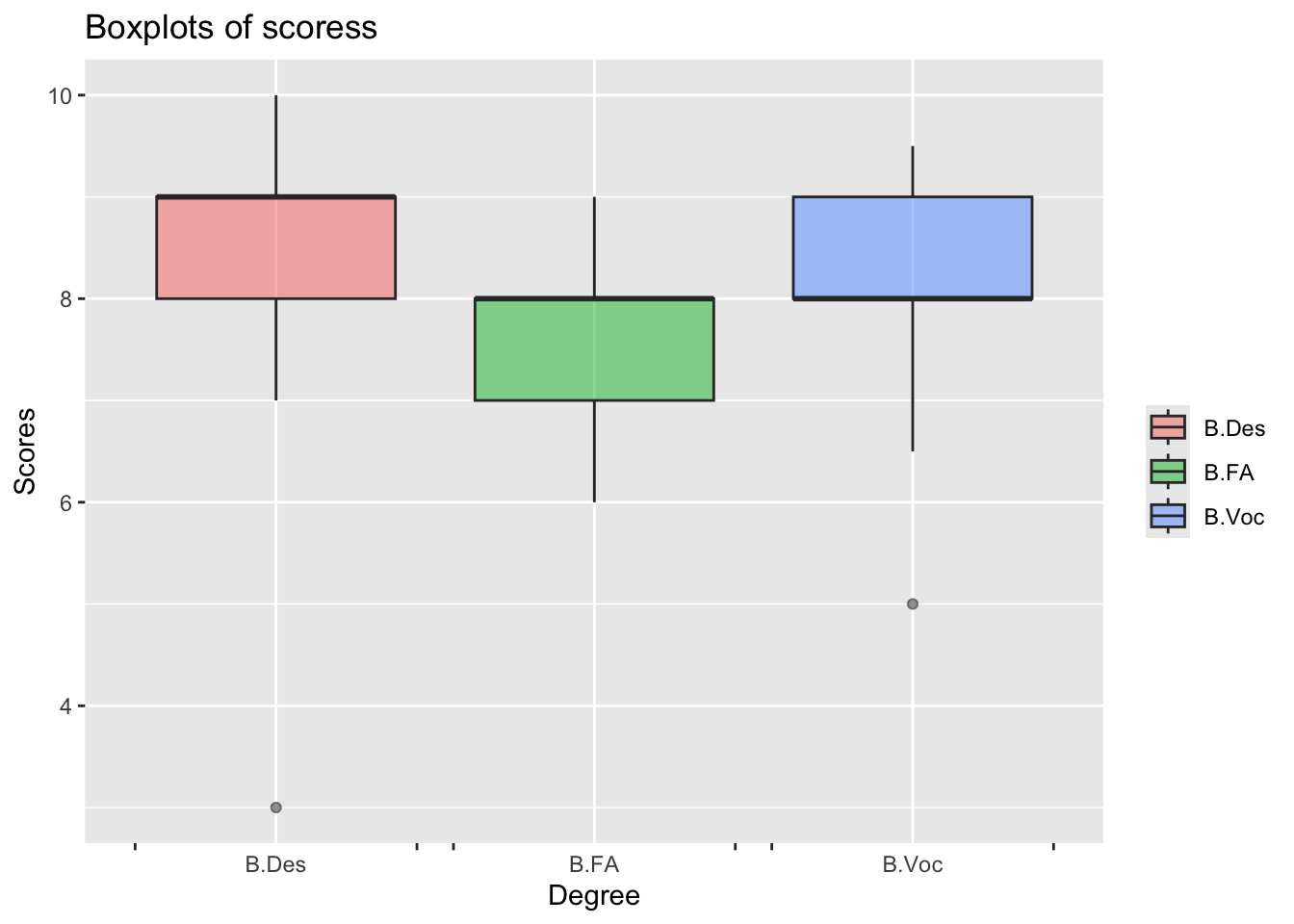
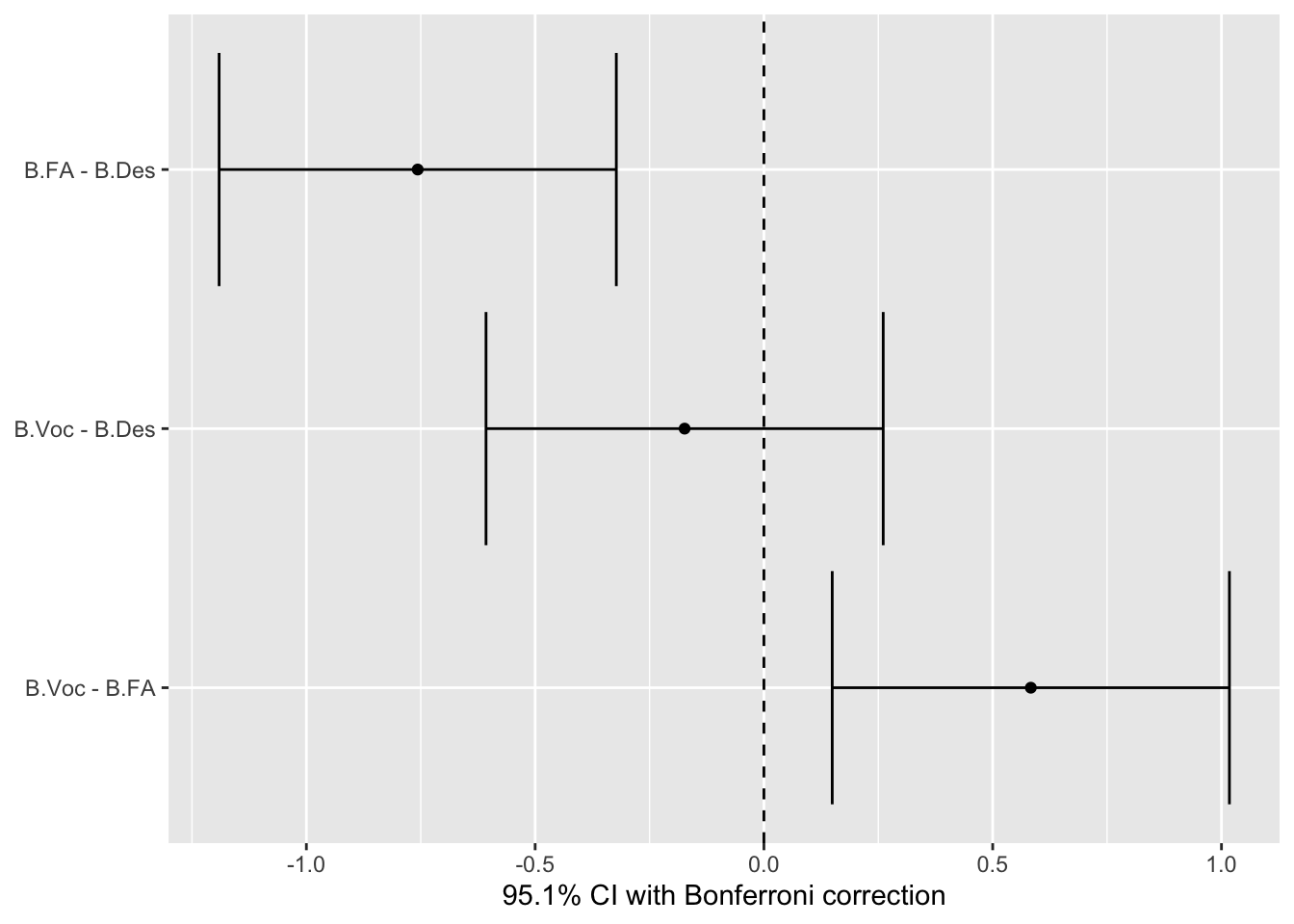
streams <-read.csv("../../data/Art, Design, and Vocation are all diff-different(Sheet1).csv")
print(head(streams)) SN Degree Course Year Letter.Grade Score Gender
1 1 B.Des CAC 2 A 8.0 F
2 2 B.Des CAC 2 O 9.6 F
3 3 B.Des IADP 2 A+ 9.2 F
4 4 B.Des CE 2 O 9.8 F
5 5 B.Des BSSD 2 P 3.0 M
6 6 B.Des CAC 2 O 9.5 F